
Within 10 minutes this database guide tells you everything about the foundation and different types of databases used (and a bit beyond to make you look extra cool).
Warning: this database guide is pretty tech heavy, you might need some coffee.
If you’ve read my ‘Machine learning guide for managers’ you know that data is the most important ingredient in any system. Whether it’s data science or a web application, without a quality data layer nothing really matters.
How does a database work?
The most fundamental database of all is the relational database. It’s also referred to as RDBMS (Relational Database Management System). Most applications are powered by a relational database in some shape or form.
How can a database go through millions of data records and retrieve so much information in milliseconds? Here is a myth debunked: it’s not about hardware speed.
This is a simplified explanation of how it really works:
1.Behind the database is something called a B-tree structure. Every record in a relational database is assigned a number (also called a key). The algorithm (= based on Big O notation) puts all those numbers in a tree like this:
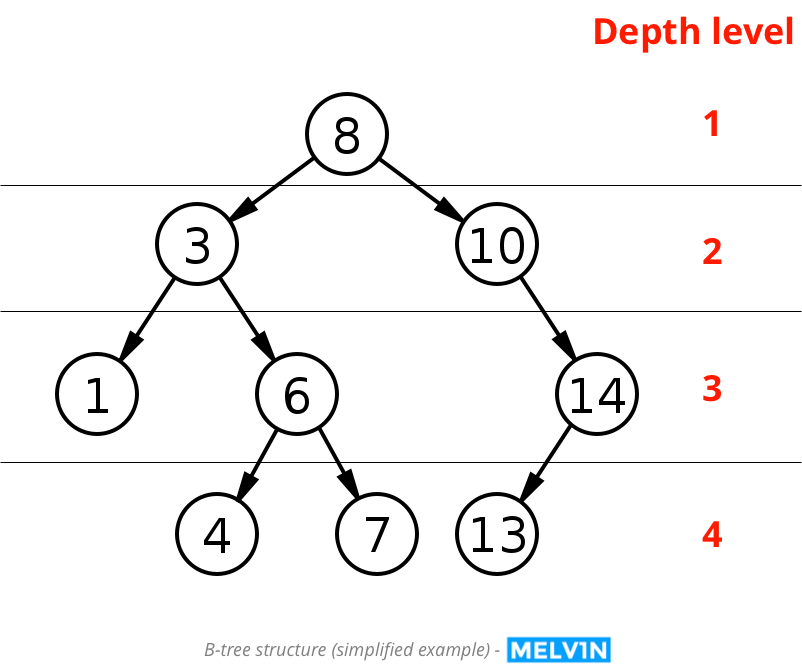
2. Now let’s say the application needs to have the data which is held by the record with the number 7. How does it go through the tree and find the number 7?
3. It’s starts with the root number (8). The next you can choose between is 3 and 10. Now here is how it knows which one to pick. It compares the number you’re searching for (7) with the current number selected (8) and select the next higher/lower number accordingly. Is 7 higher or lower than 8?
4. Answer: lower. Between 3 and 10, the lower number is 3 and it selects that. Next it needs to choose between 1 and 6. Is 7 higher or lower than 3?
5. Answer: higher. Between 1 and 6, the higher number is 6 and selects that. Is 7 higher or lower than 6?
5. Answer: higher. Between 4 and 7, the higher number is 7 and selects that. Bingo, we’ve got 7! This would be the end of the search, right?
6. Wrong. The search algorithm only got the number (key). But it didn’t read the actual data record yet. The last read is the actual data of the record.
Why does it work this way?
It’s all about the amount of reads required. Every time you progress in a B-tree you go through its depth. Every depth level is 1 read.
If you look back at the image, the number 7 is on depth level 4.
It would take 4 reads to get to 7 in a B-Tree.
It would take 8 reads to get to 7 if we just put all numbers chronologically (0,1,2,3,4….7)
So without a B-tree getting the data record would be 50% SLOWER.
Generating such a B-tree structure is what developers refer to as indexing (and mostly complain about when not done properly). Not building correct indexing massively slows down a relational database.
Wait, why would counting chronologically to 7 take 8 reads?
Unlike people, computers are programmed to start counting from 0 instead of 1.
No-SQL
No-SQL stands for non-SQL or non-relational. It means it doesn’t work like described above and doesn’t use SQL (= the language in which you talk to a relational database).
Most No-SQL databases are document based. Data is stored in documents, like the documents you read only waaaayyyyyy bigger in the amount of text.
When you request data from a No-SQL, it will first look in which document(s) the data should be and point the request to it. Then certain search mechanisms blaze through to the document to get the requested data and send it back.
No-SQL is mostly used in large-scale applications and when you need to hold large amounts of data. No-SQL powers what managers mostly refer to as big data.
Key value store
A key-value data store is somewhat different. It’s not a real database but it can hold large amounts of data. Key value data stores just store two components: a key and a value.
It looks like this:
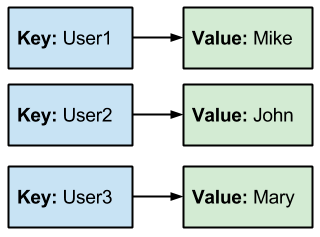
The application can request any data by the key. The key can be anything: name, number, etc. The requested will return the key plus the value of that key.
The big advantage over databases is that key-value stores are ultra-fast in getting data. This is also because databases run on the hard drive and key-value stores run in memory (reading data from memory is always faster than from a hard disk).
Key value stores are mostly used for specific application operations like holding non-persistent data, caching web pages, etc. Basically things you want to lookup fast and don’t need complex data structures for.
Data persistency: persistent vs. non-persistent
I mentioned non-persistent data, so there also is persistent data. But what does that mean?
Data persistence is about storing data in a way that is durable according to its need.
Persistent data is stored in a way that it can be held for a long period of time, is available (and recoverable) no matter hardware change or failure and can be requested no matter what device or hardware.
Usually relational databases are used to store persistent data (like user data).
Non-persistent data is data that is held for a short period of time, usually not recoverable after failure and is expected to be changed or removed within an expected timeframe.
Usually key-value stores hold non-persistent data (like cached data).
Databases explained
This list will go through the most popular databases used and some exotic ones just to give you a taste of database options most developers choose from.
MySQL / MSSQL / PostgreSQL (relational databases)
These are the most used relational databases. MySQL is by far the most popular database in use. MSSQL is basically its equivalent but mainly used within corporate/enterprise environments. Amsterdam
PostgreSQL is in particular popular amongst developers and the direct rival of MySQL. The difference is within performance and capability but for most applications this would be trivial. I would choose whichever your dev team likes most. Amsterdam reizen.
MariaDB
A special mention for my favorite relational database option, MariaDB. It’s a ‘resurrected’ version of MySQL (MySQL was eventually acquired by Oracle, making it less opensource and MySQL’s founder rivaled by creating MariaDB to counter that).
I mainly use this database because it’s fully open-source nature, flexibility, great performance and master-to-master replication.
Fun fact: MySQL and MariaDB are the only ones in the list named after real-life people, the two daughters of the founder.
MongoDB
Very popular No-SQL database. The main reason its popular because it can take any sort of data without you caring about structure. It can take anything and spit it back out in whatever way you want without losing any real performance. It’s pretty easy to scale.
It’s basically great if you’re a lazy developer or don’t want to care about database structures. In my experience, doing MongoDB backups is kind of a hassle. Make sure if you use MongoDB that you have a backup plan and it’s tested.
MongoDB was/is in particular popular amongst location based applications, because it made geospatial indexing easy out-of-the-box as one of the first.
Elasticsearch
Another popular No-SQL database is Elasticsearch. It’s mostly used to build anything related to search: search engines, application search functionality.
Unlike MongoDB, Elasticsearch is more strict in how it handles data and knowing how to use the indexing is really important.
Redis
Redis is one of the most popular key-value stores out there. It’s easy to setup and run, is extremely fast. Most developers use it or have used it.
Most developers use it for caching data but also for something else in particular: data queueing.
Wait, what is this data queue?
A data queue is what it sounds like. You can’t just plow 10.000 requests at once to any system or API. A queue puts all requests in a line and processes them accordingly. The application just gives it to the queue and can continue doing it’s own thing instead of waiting.
Aerospike
AeroSpike is basically ‘Redis on crack’. It’s brutally low-latency fast and this is the only key-value store that runs on disk instead of memory (SSD is required though).
It also fixes another drawback most key-value stores have: it can be clustered over multiple machines which makes it scalable.
This would be my key-value store of choice in any application. In my experience: setting up Aerospike is somewhat more of a hassle comparing it to Redis but worth it when you really need the performance gains.
HBase (Hadoop)
When Big Data is mentioned in any consultants Powerpoint presentation, it usually has some logos of databases. One of them I always see is Hadoop.
Hadoop is actually not a No-SQL database but is powered by one: HBase.
This one is more complex and used by the big boys. I wouldn’t touch this unless you have a serious development stack and hardcore data engineering.
Cassandra
Same goes for Cassandra, another No-SQL beast. Cassandra is an open-source No-SQL database born within Facebook. It’s great to run on commodity hardware and fault-tolerant.
But as you already can imagine, it’s meant to handle Facebook-like amounts of data.
Bonus: Kafka
Although it’s not a database, it’s worth mentioning for one reason: Kafka is used to stream data from data sources in real-time to anywhere. Kafka is like Cassandra an open-source product of a tech giant: LinkedIn.
It mostly used to process/stream large amounts of data so any applications can show it live to any users (like real-time analytics).
I’ve seen it being implemented by senior developers and be prepared for some bumps, It has some learning curve but the moment it works properly, it’s makes data so much more alive in real-time.
Liked this article? Send it to your colleagues or business contacts if you think they would like to know more about how databases work and database selection.


