
Most articles about technical debt are pretty much theory only with lots of interesting graphs. The big problem with those articles: its worth 0 without knowing how to practically implement any of it into your development operations. I’m going to give you a hands-on approach on how to manage technical debt so you can improve your product delivery (5 minute read).
Before you continue with this article…
If you’re not clear on technical debt is, please read ‘What is technical debt?‘
Why is this important?
The answer is simple: technical debt creates trouble, more debt can become deadly (for smaller companies). Technical debt is responsible for most technical trouble in every software product. It eventually creates a failing and product of bad performance. Building any new features is painful, slow and creates a lot of conflict (usually with management not understanding why it’s taking so long to build).
Competition is fierce: a less performing product means losing business to your competitor! Technical debt can become a silent killer of your company revenue.
What you will learn
How to monitor and trace technical debt because managing debt you can’t see is obviously not going to work.
How to do technical debt analysis to determine the category of technical debt, severity, etc.
How to implement technical debt in your backlog to keep it visually clear and don’t mix it up with your ongoing product development to keep all of it measurable.
How to manage debt without giving up significant delivery speed to pay off technical debt in a proportionate way and still be able to cranking out product deliveries on time.
The big picture
Let’s begin with zooming out and looking at the big picture. The difference between financial debt and technical debt is visibility. It’s not always clear how much technical debt you have at any moment in time.
Your job as a product manager managing technical debt consists of 3 elements:
- Create the ability to trace debt on the entire technology stack (bringing it to the surface).
- Do proper analysis and planning to fit in your current backlog or product roadmap.
- Execute: actually delivering structural solutions.
You can visually picture it as an iceberg where you work your way up:
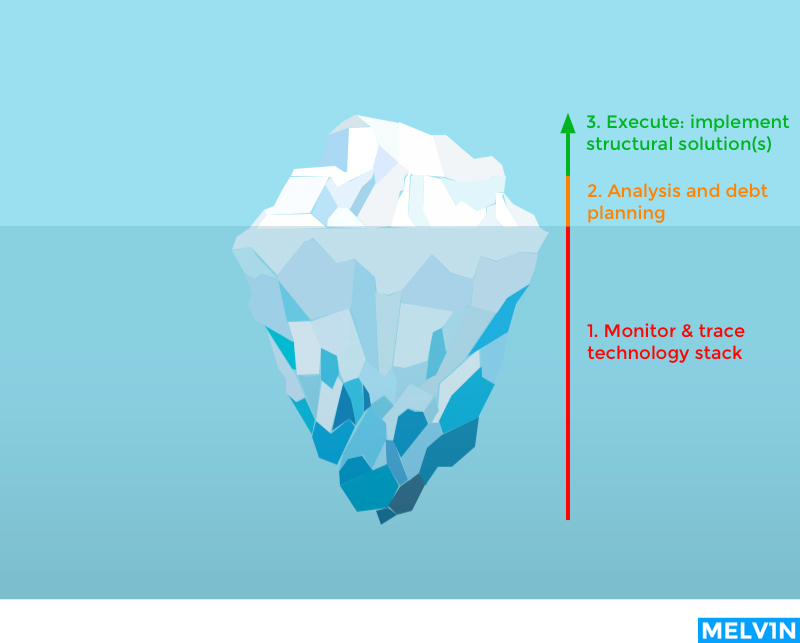
Because stack monitoring is a continuous operation the entire picture is a recurring process by its nature.
Monitor and trace technical debt
Let’s start with the first challenge: monitoring and tracing technical debt. Your application stack is not going to reveal issues by itself. The biggest symptom of technical debt in an average application is a specific issue or issues correlated to each other (by technical dependency) with a moderate-to-high-occurrence-rate.
Error tracking and tracing is a technical exercise. Luckily there are a lot of tools and platforms that can do the work for you. Here are some examples (consult your developer because it depends on your technology stack):
Tools for application error tracking and tracing
When your a small-to-midsize company, it’s best to stick with standard application error tracking. These kinds of tools trigger an alert when a user encounters an error and are easy to integrate (few minutes of work in most applications). They don’t pro-actively search for it for a simple reason: if a user isn’t bothered with it, there is no need to fix it.
Some tools you an look at (I’ve used most of them myself):
Rollbar – good integration, good at intercepting third-party script errors, UI is a bit oldskool.
AppSignal – if you run a Ruby application, probably the best solution money can buy.
Sentry – their mobile apps integration is really nice, would favor them for mobile dev.
When your a larger company, you’ll be facing a bit more complex architecture. Especially when you’re in a large microservice architecture, those tools mentioned above won’t really work for you. Errors are harder to find and don’t present themselves that easy for backend services. Even infrastructure counts as a level to monitor and trace for issues correlated to the application level (like latency).
Zipkin – most used for distributed systems to check for possible latency issues between services.
Jaeger – is partly based on Zipkin but is a bit more extensive and also checks for things like dependency issues, etc.
Logstash/Kibana – trace from your logs by centralizing and rendering errors on log level. I would favor this as the most reasonable solution if you’re not working with microservices architecture.
The 1 thing you should never forget…
Logging and error handling may contain user data. You should always exclude (or at least anonymize) user data from these logs in any way possible. Processing user data in (error) logs without consent or proper data handling protocol may result in trouble with data regulations like GDPR.
Technical debt analysis
Once issues have surfaced, you’re only pass the first stage. Analysis of technical debt has 1 specific goal: measuring impact. You can’t plan or prioritize anything without knowing its impact.This is in most cases directly correlated to user value, like a serious payment issue (impact) that prevents users from using a certain payment method (user value).
Analysis: grading your debt
Now the point of the analysis is not from a technical point-of-view yet. You as a product manager can’t figure out the root cause. We need to focus on impact for the user (value) first. So we’re going to put a number on it first from the impact point-of-view.
Exercise time: You’re going to grade every issues on three levels: Severity, Occurrence and Dependency. You’ll grade every issue on every level between 1 till 5. Where 5 is the most heavy. You need to do this a few times before the get the hang of it.
Severity (1 – 5 = users can’t use your product) is about how much the user is disturbed or prevented from using your product. If technical trouble really makes it hard for your user to use your product, this should be more towards 5. Real deal-breakers or show-stoppers are 5 by default.
Occurrence (1 – 5 = at least in top 5 of error tracking occurrence) is about the amount of times any user encounters the specific issue. Application error tracking tools do this for you. Just make use of that feature. It’s important to correctly correlate the technical error with the right issue(s). Some errors represent multiple issues because of their (data) dependencies.
Dependency (1 – 5 = complex data dependencies) is about if an issue is attached to certain technical dependencies that need to be fixed/changed when addressing the issue itself. Meaning: you can’t fix that issue without including changing another part of the system. The more technically complex dependencies should be graded towards level 5.
When you’ve grade an issue, you just add up the numbers of all three levels. Put all issues in a list for yourself with those total grades. Now you’ll have a base of prioritization of technical debt issues which you can start using in your backlog.
Now we have the base, we can proceed to the operational side of product, execution technical debt.
Execute: implement structural solutions
The first thing you show know about paying off technical debt…that it actually works like financial debt: you pay off your debt in terms.
So this is our gameplan…
1. Dispatching hot fixes
Everything with a Severity level 5 is eligible for something called a hotfix. It’s basically a patch on the wound which is mostly already technical debt by itself. This fix is temporary and immediate to give you some breathing space to investigate the long-term fix for the issue without disrupting the experience for the user any longer. This is basically a weapon you only use prior to a Spike allocation for the long-term solution to maintain a proper user experience.
2. Backlog planning: allocating investigation Spikes
Using Spikes in sprints is a very handy tool to allocate timeframes where you allocate appropriate resources to technically investigate the issue. Your developers get the time and space to really dive into the system and properly document the issue, find dependencies, present their findings and discuss possible solutions within the team.
The result of Spikes are solutions which the team have decided to go for implementation. In worst cases when a Spike doesn’t result in a solution yet, take the outcome of that Spike and allocate it to a new one. Don’t keep a Spike infinitely open, take those steps in new Spike(s) to document progress on the solution.
Once you’re ready for implementation, you’ll go to the last step.
3. Backlog planning: planning debt stories
Congrats, you’ve made it to the easy part. Well, compared to all the work you already did off course. The important part of technical debt stories is to keep track of them and group them in your backlog. This way can always have an overview and easily report to your stakeholders on how you’re being a kung-fu master on technical debt.
Most of you use Jira as your backlog tool. My favorite solution would be to have a dedicated Epic for technical debt (because of the nice label you get on sprint view with stories). But you can only assign 1 Epic to an story. The other drawback is that all component/version/labels work for 1 project. So an overview over an entire technology stack separated into multiple projects won’t work either.
The solution for this problem: the structure plugin for Jira. You can organize technical debt stories into an overview for 1 project or company-wide.
The amount of debt you plan in a sprint is based on your roadmap and how much you think you need to pay off to keep your product development healthy. In legacy environment I would go for at least 5%-10% of sprint resources capacity.
Conclusion: embrace technical debt like your DNA
Like I said before, technical debt and financial debt are pretty much alike. The only big difference: no software or technology will ever be debt-free. Don’t see it as something to pay off as fast as possible. No company in the world has the resources to pay off their technical debt in one go.
Even if you make brand new software. You’ll inherit technical debt faster than you think.
Technical debt is basically part of your systems DNA. Our goal is to manage this part of our technical genetics so it doesn’t turn into a systematic disease.


